

System level security for open source AI models
"Security" and "privacy" are on everyone's mind as we move towards adoption of GenAI in the enterprise. Yet, these terms are confusing and bloated. Often engineering organizations are left confused when it comes to securing their AI-driven applications. Publications like the NIST AI Risk Management Framework and the OWASP Top 10 for Large Language Model Applications provide some guidance, but they can also be overwhelming. The challenge lies in figuring out how to apply these frameworks practically in real-world settings.
AI risks and definitions
Drawing on helpful resources that those from OWASP, let’s first define some AI security risks that should be on your radar:
-
Prompt Injection or jailbreaking: A prompt injection vulnerability occurs when specific user inputs manipulate a language model's behavior or output in unintended ways, potentially causing it to violate guidelines, generate harmful content, enable unauthorized access, or influence critical decisions. These inputs can affect the model even if they are imperceptible to humans. Prompt injection vulnerabilities exist in how models process prompts and can be exploited to alter the model's behavior, including bypassing safety measures (known as jailbreaking).
-
Sensitive information disclosure and PII/PHI leaks: Sensitive information disclosure occurs when a language model or its application inadvertently reveals personal identifiable information (PII), financial details, health records, confidential business data, security credentials, legal documents, proprietary algorithms, or source code through its output. This can lead to unauthorized data access, privacy violations, and intellectual property breaches. Users should be cautious about providing sensitive data to LLMs and understand the risks of unintended disclosure.
-
Supply chain vulnerabilities: Supply chain vulnerabilities in LLMs refer to the various risks that can compromise the integrity of training data, models, and deployment platforms throughout the supply chain. These vulnerabilities can lead to biased outputs, security breaches, or system failures. In addition to traditional software risks like code flaws and dependencies, LLMs are susceptible to threats from third-party pre-trained models and data, which can be manipulated through tampering or poisoning attacks. The use of open-access LLMs and fine-tuning methods, as well as the emergence of on-device LLMs, further exacerbate these supply chain risks.
-
Insecure output handling: Insecure output handling, or lack of output validation, refers to insufficient validation, sanitization, and handling of outputs generated by large language models before they are passed downstream to other components and systems. This vulnerability can be exploited when LLM-generated content is controlled by prompt input, providing users indirect access to additional functionality. Improper output handling can result in various security issues such as Cross-Site Scripting (XSS), Cross-Site Request Forgery (CSRF), Server-Side Request Forgery (SSRF), privilege escalation, or remote code execution. Factors that increase the impact of this vulnerability include granting the LLM excessive privileges, vulnerability to indirect prompt injection attacks, inadequate input validation in 3rd party extensions, lack of proper output encoding, insufficient monitoring and logging of LLM outputs, and absence of rate Sensitivlimiting or anomaly detection for LLM usage.
-
Excessive agency: Excessive agency is a vulnerability in LLM-based systems where they can perform damaging actions in response to unexpected, ambiguous, or manipulated outputs. This can be caused by issues such as hallucination/confabulation from poorly-engineered prompts or direct/indirect prompt injection from malicious users. The root causes typically involve excessive functionality, permissions, and autonomy. The impacts can range across confidentiality, integrity, and availability, depending on the systems the LLM-based application can interact with. Attackers can manipulate these systems, causing them to execute malicious actions and pose significant security risks.
Failing to address GenAI and LLM security risks can expose organizations and customers to data breaches, unauthorized access, and compliance violations. These risks are context-dependent and can impact various aspects of an organization's operations. Rapid adoption of LLMs and the evolution of GenAI applications have outpaced the establishment of comprehensive security protocols, leaving many applications and organizations vulnerable to high-risk issues.
Common risk mitigations (and associated shortcomings)
Frontier, closed model providers like Anthropic and OpenAI and open source projects have taken certain steps to address these security vulnerabilities. Let’s look at a few of these to understand their advantages and disadvantages.
Model Alignment (link 1, link 2):
-
Definition: The process of encoding human values and goals into large language models (via fine-tuning, i.e., modification of the model weights) to make them helpful, safe, and reliable, tailored to follow business rules and policies.
-
Advantages: Helps ensure AI models advance intended objectives and follow desired behaviors (i.e., to bias them in a certain way), promoting alignment with operator's goals.
-
Shortcomings: Difficult to specify full range of desired and undesired behaviors, leading to use of simpler proxy goals that may overlook necessary constraints or reward mere appearance of alignment. As such, alignment will never create “jailbreak free” or “fully-aligned” models.
Intentional system prompt injections (link 1, link 2, link 3):
-
Definition: Behind-the-scenes instructions that guide AI on how to behave throughout an interaction, including understanding the main objective of a task, structuring output, preserving user's content, offering improvements, and ensuring clear reasoning. Often these instructions are “injected” intentionally and automatically into all user-provided system prompts (outside of a user’s control).
-
Advantages: Provides detailed technical, domain-specific and relevant information to optimize AI model performance or behavior.
-
Shortcomings: LLMs do not always follow intentional system prompt injections consistently. New attacks are continuously developed to reverse engineer these injected system prompts and bypass instructions.
Guardrails or input/output filters:
-
Definition: Programmable systems that sit between users and AI models to filter/ modify/ or validate inputs and/or outputs. These operate within defined principles of an organization and are added as pre or post processing layers (e.g., to filter out PII on the inputs to a model or block toxic language on the output)
-
Advantages: Enables organizations to leverage generative AI while programmatically mitigating or monitoring for certain specific risks.
-
Shortcomings: Guardrail wrappers around external AI systems cannot control actual behavior or inherent vulnerabilities in LLMs. Adding layers in front of and behind LLMs increases latency and expense of requests. False positives can be annoying for users.
While these techniques are valuable and a piece of the overall AI security puzzle, they clearly have limitations.
System level AI risk management
Because each mitigation mentioned above is only a piece of the puzzle, and, further, there are security issues that are not addressed by any of these mitigations, we like to take a more systematic view of AI security. Threats related to LLMs (or other GenAI models) can occur at various stages of the AI development lifecycle. To address these vulnerabilities holistically, risks can be categorized into three stages: pre-deployment, deployment, and online operations.
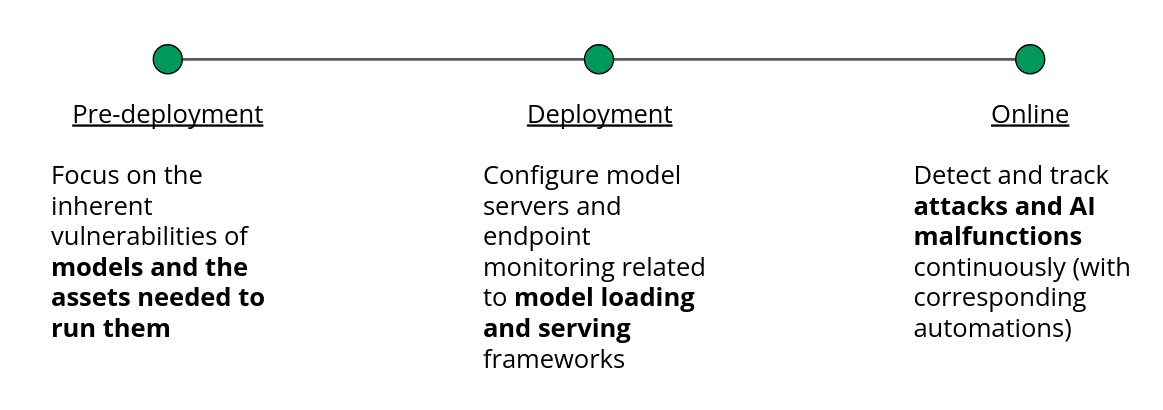
1. Pre-deployment
Supply Chain Vulnerabilities:
Open-source LLMs often introduce risks through deserialization of model weights, such as using pickle files, which can execute arbitrary code. Mitigation strategies include:
- Using tools like safetensors for secure serialization (Hugging Face Documentation).
- Performing static code analysis on model files.
- Verifying checksum and model signatures to ensure file integrity.
While these methods reduce risks, they are not foolproof. For example, transitioning from pickle to safetensors may introduce other vulnerabilities (link). Thus, it is critical to evaluate infrastructure holistically.
Model Poisoning:
Adversaries may upload models trained on malicious datasets designed to produce biased or harmful outputs. Best practices to counter this include:
- Testing models on adversarial datasets before deployment.
- Conducting prompt sensitivity analysis to assess how minor changes in prompts affect outputs (Hugging Face Blog).
- Simulating agentic behavior to identify unintended model decisions (Wired Article).
2. Deployment
Secure model loading and configuration:
During deployment, risks include improper storage of model parameters and insecure loading practices. Recommendations include:
- Storing sensitive configurations securely (e.g., top-k settings can be hidden to avoid misuse).
- Loading models from secure checkpoints (e.g., from_flax) to prevent code execution vulnerabilities.
Running models in isolated environments (sandboxes) reduces exposure to external threats. Implementing strict whitelists for Python dependencies and frequently updating them ensures a secure ecosystem.
3. Online
Online risks involve real-time interactions with the model. These can be further categorized into input-level threats and output-level threats to better manage risks.
Input-level threats:
- Sensitive Data Exposure: Sending proprietary or personal data to black-box APIs (OWASP GenAI Risk Guide).
- Prompt Injection Attacks: Manipulating prompts to produce unintended outputs (OWASP GenAI Risk Guide).
Input-level mitigations:
- Prompt injection detection systems that block malicious inputs.
- Differential privacy techniques to safeguard sensitive information.
- Integrating multilingual and multimodal input safeguards.
Output-level threats:
- LLM outputs could include code, SQL queries, markdown, or scripts that, if executed/ presented, would introduce vulnerabilities (such as remote code execution)
- LLMs can output toxic or otherwise harmful text (curse words, hate speech, etc.)
- Outputs from models often include information that isn't factually correct or appropriate given the context
Output-level mitigations:
Ensuring outputs are moderated and factual is essential. Key measures include:
- Toxicity and hazard category checks for generated content.
- Verifying the factual accuracy of responses, particularly in retrieval-augmented generation (RAG) systems.
- Adding watermarks to outputs for traceability and accountability.
A platform built for system level AI security
All of these threat mitigation strategies can be overwhelming, and the concerns related to AI are evolving. Prediction Guard has been built from the ground up to easily enable the appropriate mitigations for high security, private AI applications. These are seamlessly integrated into the platform. Please reach out if we can be helpful as you work to secure your AI deployments! Book a call here or join our Discord to chat.